Это любительский перевод статьи, оригинал которой располагается по адресу:
http://arstechnica.com/old/content/2007/10/the-audiofile-understanding-mp3-compression.ars
Copyright (C) 2012, Audiophile
Полное или частичное копирование текста допускается только с письменного разрешения автора.
От неизвестности к повсеместности
Со времен своей стандартизации в 1991-м MP3 прошел путь от малоизвестной части видео файла до такой распространенности, о которой большинство проектов может только мечтать. Он везде – на полках магазинов с плеерами, на устах политиков и адвокатов, защищающих интеллектуальную собственность.
Но что такое MP3? Чаще всего ответ бывает двух типов. Первый, длинный – техническая документация полная характерной терминологии и переполненная математикой. Второй, краткий, чаще всего используемый нетехническими периодическими изданиями; обычно в нем говорится, что в процессе преобразования удаляются звуковые составляющие, как правило не воспринимаемые человеческим ухом. Но это единственное предложение вызывает больше вопросов, чем дает ответов, для любого более-менее технически образованного читателя. Каким образом происходит выбор этих неслышимых звуков и как они удаляются? Какая разница между различными битрейтами и уровнями качества? Если Вы чем-то походите на меня, то Вы тоже хотели бы знать механизм работы MP3, но конечно не до такой степени, чтобы суметь написать свой собственный кодер.
Эта статья – попытка объяснить процесс MP3 компрессии доступными терминами, но не слишком упрощая. Хотя, отдельные этапы (такие как подробности схемы стерео кодирования и углубление в структуру файла) всё же опущены, эта статья включает в себя базовую теорию получения из несжатого аудио файла звука сжатого в MP3. Для того чтобы в процессе экскурса в кодек MP3 не перегружать вас техническими мелочами, мы рассмотрим изначальные принципы кодирования MP3 и его предшественников, затем перейдем к анализу и сжатию и, наконец, к влиянию этого формата на цифровой звук в целом.
Слушай
В зависимости от количества концертов, которые Вы посетили, Ваши уши могут быть в более или менее хорошем для Вашего возраста состоянии. Но даже если они в прекрасной форме, человеческий слух всё равно имеет определенные ограничения. Тесты обычно показывают, что в лучшем случае мы можем слышать частоты в диапазоне от 20 до 20000 Гц. Также наши уши более чувствительны к частотам в пределах 2-5 кГц и могут в данном диапазоне определять изменение частоты на 2 Гц – это и есть эффективное «разрешение» слуха. По мере того как человек стареет или чувствительные клетки уха поражаются громкими звуками, верхний частотный порог слышимости снижается. Фактически, большинство взрослых (включая меня) имеет проблемы с восприятием частот выше 16 кГц.
И это только физические ограничения человеческого уха. Наш мозг тоже играет роль в фильтрации и анализе сигналов получаемых по слуховому нерву. Наука, изучающая восприятие звука человеком, называется психоакустика, и она открыла несколько полезных слуховых эффектов. Например, мой любимый – эффект Хааса, заключающийся в том, что два одинаковых звука приходящих с промежутком в 30-40 мс из разных источников, будут восприниматься как один, звучащий из первого источника. Этот эффект часто используется на публичных выступлениях, чтобы усилить звук идущий со сцены – даже если дополнительные источники находятся далеко в стороне. MP3, как и многие другие алгоритмы кодирования с потерями, во многом опирается на подобные психоакустические эффекты. В частности, он использует явление частотной маскировки.
Представьте два звука несильно отличающихся по частоте – скажем, 100 и 110 Гц – но разных по мощности. По отдельности более тихий звук прекрасно слышен, но если оба звука воспроизвести одновременно, слышен будет лишь тот, который громче. Процесс сокрытия одной частоты другой близкой по значению (но не идентичной) называется частотной маскировкой. Степень, в которой одни частоты могут маскировать другие, зависит от частотного диапазона – наши уши менее чувствительны в области низких и высоких частот. Громкие переходные сигналы (щелчки и пр. – сигналы с очень короткой длительностью) также могут маскировать более тихие звуки на небольшое время, как в случае с эффектом Хааса. Этот тип маскировки называется временнОй и также используется в MP3 сжатии.
Пережитки прошлого
Еще одна вещь, которую необходимо помнить, изучая работу алгоритма MP3: он является непосредственным наследником более старых алгоритмов компрессии, что в значительной мере повлияло на его устройство. MP3 расшифровывается как MPEG-1 Audio Layer 3. MPEG, в свою очередь, расшифровывается как Moving Pictures Expert Group – это название группы создавшей стандарт. MPEG видео (а также его преемники MPEG-2 и MPEG-4) используется повсеместно – DVD представляет собой модифицированную версию MPEG-2, коим также является сигнал цифрового ТВ.
Кроме третьего слоя (Layer 3) спецификации MPEG-1, существуют и два предыдущих, которые, однако, не прижились среди пользователей (согласитесь, немногие из нас слушают дома MP2). В MP3 есть некоторые функции, которые явно безосновательно усложнены и выполняются в значительно большее количество этапов, чем необходимо, чаще всего это и есть пережитки прошлого – наследие полученное от предшественников. Таким образом, алгоритм MP3 не лишен недостатков и порой слабо рационализирован.
Это является большим оправданием для меня, как для автора, честно. Так что, если у вас проблемы с пониманием процессов описанных в этой статье, не вините меня за скудные пояснения, вините Layer 2.
Анализируй
Что ж, давайте начнем с обычного звукового файла в виде несжатого PCM аудио. Для простоты предположим, что и этот файл, и MP3 будут иметь одну частоту семплирования – MP3 поддерживает различные частоты дискретизации, но наиболее распространенной является частота дискретизации Audio CD – 44.1 кГц.
Первым этапом является группировка этих семплов во фреймы, каждый из которых содержит 1152 семпла. Почему 1152? Это очередная дань прошлому – обратной совместимости с Layer 2. Технически фреймы у Layer 3 разделены на две гранулы по 576 семплов. Это такой себе клудж ("ляп"), который был устранен в более новых кодерах: когда создавался стандарт MPEG-2 видео его звуковая часть использовала одну гранулу (1152 семпла) в каждом фрейме. В целях кодирования MP3 на самом деле использует в каждый момент времени только одну гранулу, хотя он может частично использовать предыдущие и последующие гранулы – с тем чтобы более тщательно анализировать поведение сигнала.
Далее эти семплы проходят через банк фильтров, который разделяет звук на 32 частотных диапазона (в некоторых программах для обработки звука это называется полосовым фильтром – bandpass filter). Это также является наследием от Layer 2, который фактически использовал эти 32 полосы частот для кодирования. Одним из достоинств Layer 3 является то, что он дополнительно разделяет каждый из этих 32-х диапазонов еще на 18 частотных полос, создавая 576 меньших, адаптивных полос. Каждая из этих полос содержит 1/576-ю часть исходного частотного диапазона.
На данном этапе протекает два параллельных процесса: модифицированное дискретное косинус-преобразование (МДКП, MDCT) и быстрое преобразование Фурье (БПФ, FFT). Математика этих процессов весьма сложна, но объяснить их можно и более-менее простым языком.
FFT используется как функция анализа, преобразовывая каждую полосу частот в информацию, которая может быть передана психоакустической модели кодера (что-то вроде виртуального человеческого уха). Кодер использует эту модель чтобы ответить на такие вопросы как: есть ли в каждой отдельной полосе частот звуки ниже порога маскировки (которые будут скрыты более громкими звуками близкими по частоте)? Является ли звук более-менее постоянным или он изменяется? Имеются ли какие-то резкие всплески (щелчки, транзиенты), которые должны быть сохранены и которые должны скрыть другие всплески до или после? Эта информация будет использоваться на протяжении сжатия чтобы выяснить, какие данные (согласно психоакустической модели) могут быть исключены без ущерба для воспринимаемого нашим ухом звучания.
Перед переходом к параллельно протекающему MDCT преобразованию фрагменты аудио сортируются по сложности – в зависимости от динамики содержащегося в них сигнала. MP3 позволяет описывать частотные полосы, используя один из двух типов блоков (т.н. windows) – длинный или короткий. Постоянный, не изменяющийся со временем сигнал может быть описан с помощью одного длинного блока. Транзиенты же – например, ударные инструменты или согласные звуки в человеческой речи – описываются с помощью трех коротких блоков (каждый из которых содержит по 192 семпла – примерно 4 миллисекунды).
MDCT преобразовывает разбитую на блоки полосу частот в последовательность спектральных значений. В отличии от обычного представления аудио – где сигнал описывается уровнем звукового давления в заданные моменты времени – спектральный анализ описывает звук как распределение мощности по диапазонам частот на каждом отдельном промежутке времени.
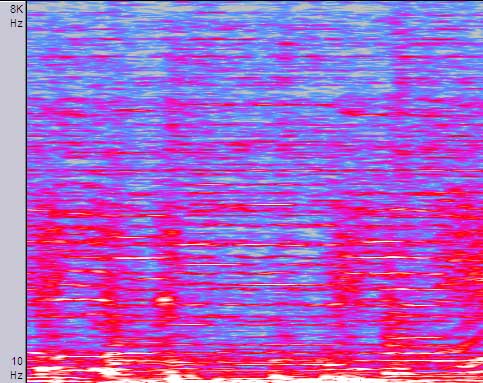
Перед Вами спектрограмма – спектральное представление звукового файла. Частоты, на которые приходится больше мощности (энергии) изображаются более ярким цветом. Снизу-вверх – низкие/высокие частоты, по горизонтали откладывается время.
Поскольку спектральное представление сигнала имеет большее сходство со слуховым восприятием звука, большинство lossy кодеров используют именно его для исключения неслышимых человеком частотных составляющих, вместо того чтобы оперировать дискретизированной звуковой волной. Как только MDCT преобразование завершается, MP3 имеет в своем распоряжении 576 "бинов", каждое из которых описывает интенсивность 1/576 части всего спектрального диапазона.
Теперь, когда у кодера есть спектральная информация и результаты психоакустического анализа гранулы, начинается собственно сам процесс сжатия.
Холодное сжатие
MP3 опирается на два типа компрессии, только один из которых использует психоакустический анализ. Психоакустическая компрессия идеальна для уменьшения сложных по характеру звуков с большим количеством составляющих, т.к. они предоставляют широкие возможности маскировки. Более простые звуки не выигрывают по степени сжатия от психоакустики, но очень легко сжимаются с использованием более традиционных методов компрессии. Совмещение обоих подходов требует двух-проходного процесса квантования и кодирования по Хаффману, взаимодействие которых обеспечивает впечатляющую гибкость сжатия.
Слово «квантование» звучит весьма пугающе, но сводится это к процессу количественной оценки, иначе говоря, к присваиванию определенного численного значения. «Но у нас уже есть числа» – возразите Вы. Это так. Но MP3 не был бы алгоритмом компрессии, если бы только преобразовывал числовые данные из одной формы в другую.
И так, 576 бинов, полученных после MDCT преобразования, распределяются на 22 масштабнокоэффициентных полосы (scalefactor bands). Путем деления каждого значения в каждой отдельной полосе на заданное число (квантователь), достигается некоторая аппроксимация исходных значений, при этом часть информации из-за ошибки квантования теряется. Квантование одинаково для всего частотного спектра, но для каждой масштабнокоэффициентной полосы используется свой коэффициент масштабирования, т.е. своя точность. Большие значения меньше теряют в точности при процессе квантования, в то время как небольшие значения в значительной степени страдают от ошибки квантования. В процессе декодирования масштабирование компенсируется, потому на уровне громкости квантование практически не сказывается.
Быстрое преобразование Фурье (FFT) выполнялось именно с тем, чтобы в дальнейшем иметь возможность задавать точность необходимую для каждой масштабнокоэффициентной полосы. Если в полосе имеются слабые сигналы, которые будут маскироваться в данной полосе более сильным, коэффициент масштабирования данной полосы может быть уменьшен таким образом, что маскируемые сигналы будут исключены. К сожалению, ошибка квантования также имеет слышимый эффект (проявляется как шум), и, чем меньше уровень масштабированного сигнала, тем выше будет уровень шума после восстановления исходной амплитуды. Таким образом, вторая функция психоакустической модели – отслеживать, когда соотношение сигнал/шум станет таким, что впоследствии сможет восприниматься на слух. Когда это происходит, кодер возвращается к этапу квантования и увеличивает точность аппроксимации (коэффициент масштабирования).
Это может показаться сложным и непонятным, так что давайте рассмотрим данный процесс на гипотетическом примере. Пусть наша информация о несжатой масштабнокоэффициентной полосе представлена числом 12592. И мы должны произвести квантование путем деления на 100. Таким образом, при масштабном коэффициенте 1.0 (без изменений), мы запишем это значение как (12592*1.0)/100 = 126, в дальнейшем, восстанавливая значение при декомпрессии (умножая его на исходный квантователь), мы получим 12600. Мы пожертвовали точностью и внесли небольшой шум квантования – наше число отличается от исходного на 8, но всё равно очень близко к нему.
В случае если мы можем позволить себе более низкую точность и более высокий шум, можно масштабировать входные данные с помощью множителя 0.1 – получим 1259. После квантования (квантователь – 100) получим 13. Восстанавливая значение, мы используем как квантователь, так и масштабный коэффициент, получая на выходе (13*100 )/0.1 = 13000. Теперь мы потеряли немного больше информации, но вполне возможно, что эти потери не будут заметны – это зависит от конкретного случая. Но главное, что эти короткие значения занимают меньше места в файле, особенно в сочетании со следующим этапом сжатия.
В то же время, вместе с квантованием и масштабированием MP3 кодер также использует кодирование по Хаффману – с тем чтобы преобразовать информацию о масштабнокоэффициентных полосах в более короткие двоичные строки. Кодирование Хаффмана (названное так в честь кандидата наук Массачусетского института технологий, разработавшего этот метод в 1952-м году) представляет из себя что-то вроде дедуктивной игры «двадцать вопросов» в двоичном коде. Начиная с верха дерева, содержащего все возможные ответы, компьютер считывает информацию, спускаясь вниз по ветвям, каждой из которых присвоено значение 0 или 1. Ответы содержатся в конце ветви, так что, как только компьютер считывает верный ответ, он прекращает движение по ветви.
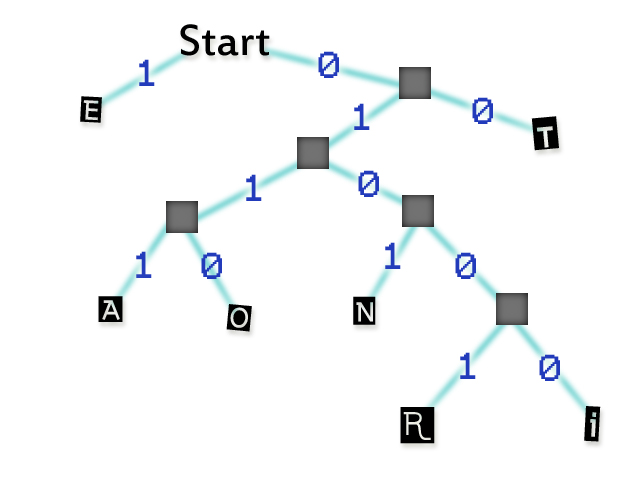
Наиболее вероятные ответы расположены близко к вершине (как на примере ниже, который иллюстрирует кодирование наиболее часто встречающихся букв английского языка). Ключевым моментом является именно то, что алгоритм прекращает перемещение по ветви, как только находит ответ. Наиболее часто встречающиеся ответы могут быть записаны в виде очень коротких значений (в примере ниже, если код начинается с 1 вместо 0, записывается буква «Е» и немедленно выполняется переход к следующей последовательности).
Эти коды могут быть изображены в виде дерева, но для компьютерной программы они – обычная таблица, и как только компьютер находит совпадение, он переходит к следующему символу.
| E | 1 |
| T | 00 |
| A | 0111 |
| O | 0110 |
| N | 0101 |
| R | 01001 |
| I | 01000 |
MP3 использует несколько таблиц Хаффмана для квантованных значений и может выбирать разные таблицы для представления различных масштабнокоэффициентных полос. Меньшие (менее точные) значения располагаются вверху таблиц. Используя таблицы Хаффмана, кодер регулирует качество для получения на выходе заданного битрейта. Если в конце этапа квантования он обнаруживает, что блок кодированных битов длиннее, чем позволяет битрейт гранулы, кодер возвращается к регулировке коэффициента масштабирования и уменьшает его (таким образом получая на выходе меньше битов, в т.ч. после сжатия по Хаффману). С другой стороны, если кодер не достигает установленного битрейта, он опять же возвращается и увеличивает уровень отдельных частот, тем самым повышая точность квантования.
Вот, в общем-то, и всё, что необходимо для кодирования гранулы. Каждая гранула состоит из двух частей необходимых для восстановления аудио: масштабные коэффициенты для каждой полосы и длинная последовательность битов Хаффмана. Но, как говорилось ранее, MP3 базируется на фреймах, каждый из которых включает две гранулы. После завершения двух гранул, кодер объединяет их в один фрейм для передачи. MP3 файлы имеют довольно простую структуру, с большим количеством аудио данных и ID3 метаданными (тегами) записанными в начале файла.
Кроме того, фрейм также содержит в своем заголовке большое количество вспомогательной информации. Например, здесь содержится код синхронизации, которым начинается каждый фрейм, именно поэтому декодеры могут проигрывать частично поврежденные файлы. После синхрокода в фрейме находится информация о битрейте, что позволяет некоторым фреймам использовать больший битрейт, если они содержат больше информации (VBR кодирование). Ну и, наконец, в заголовке фрейма располагается информация о количестве каналов (стерео или моно), частоте дискретизации (семплирования), а также пометка о защите материала авторскими правами.
И так, теперь, когда мы рассмотрели процесс преобразования цифрового звука в MP3, Вам наверное интересно, каким образом происходит обратное преобразование. Хотя структура декодера и не является полной инверсией кодера, она близка к этому. При декодировании биты Хаффмана преобразовываются обратно в квантованную информацию, масштабируются до исходного уровня, а затем складываются друг с другом, давая на выходе поток PCM (ИКМ – импульсно-кодовая модуляция) семплов, которые могут быть воспроизведены с помощью обычной звуковой карты.
Превращение
Переход к MP3 оказал небывалое влияние на цифровой звук. Мало того, что он поспособствовал повсеместному распространению портативных плееров, он также оказался в центре всех дискуссий на тему интеллектуальной собственности и пиратства. Конечно, были умельцы, которые распространяли музыку в громоздких WAV и AIFF форматах через группы новостей (IRC, etc), но возникла новая, простая в использовании пиринговая файлообменная сеть Napster, которая стала одной из торговых марок, связывающих музыкальную индустрию с потребителем. В то же время, MP3 поспособствовал созданию новой онлайновой системе дистрибуции, которая (в некоторой мере) демократизировала музыку и радио через MySpace и подкасты.
Могло ли это всё произойти без MP3? Почти наверняка. В конце концов кто-то популяризировал бы другой метод уменьшения размеров аудио файлов, или же проблему свело бы на нет увеличение пропускной способности сетей. P2P сети могли бы задержаться в развитии, но они всё равно бы появились, дабы мы с Вами могли воспользоваться преимуществами распространения цифрового контента. Тем не менее, вполне вероятно, что формат, который занял бы место MP3, скорей всего использовал бы те же самые базовые принципы, включая психоакустическое моделирование и сжатие данных.
В самом деле, это поразительно: как много важнейших элементов MP3 отсылает нас к теоретическим трудам более чем полувековой давности. Кодирование Хаффмана датировано 1952-м годом. Новаторская работа Клода Шеннона на тему сжатия с потерями и соотношений сигнал/шум была написана во время Второй мировой войны. Исследования ограничений человеческого слуха и восприятия – например, эффекта Хааса и кривых равной громкости – и того старше. Теорема Гарри Найквиста была открыта в 1927-м и предназначалась для связи по телеграфу! Так или иначе, MP3 – это отнюдь не новое изобретение, но принявшее современную форму.
И все же MP3 удалось сохранить свои позиции на потребительской арене, даже не смотря на появлении новых, технически более совершенных форматов. В последнее время, особенно с появлением цифрового управления правами (DRM), появилось большое количество форматов – как с открытым исходным кодом, так и проприетарных – но MP3 всё равно продолжает оставаться в интернете стандартом де-факто, и нет никаких предпосылок для изменения нынешнего положения вещей. Не смотря на то что MP3 может быть презираем поклонниками аналогового и lossless аудио за вносимые им искажения, надо признать, что он в корне изменил наше представление о музыке и звуке в целом.
Автор хочет выразить свою благодарность Габриелю Бувинь – одному из разработчиков кодера LAME – за терпение и технические подробности. Больше информации о процессе MP3 кодирования, а также значительное количество технической документации Вы можете найти на его веб-сайте: www.mp3-tech.org.
Информация от спонсора
PDALife.info: новости мобильных технологий. Здесь, кроме всего прочего, Вы можете узнать последние новости iphone, а также прочитать обзоры новинок компании Apple.
 , тем более что всегда узнаешь чегонить новое (упущенное). За перевод збазиб!
, тем более что всегда узнаешь чегонить новое (упущенное). За перевод збазиб!
